Поиск выгодных цен на товары при помощи алгоритмов машинного обучения


Коротко, но подробно о том, как работает еще один компонент комплексной системы управления закупками — наш узкоспециализированный поисковик по товарным прайсам. Кому и зачем необходим такой инструмент, как он помогает сохранить деньги и ускоряет принятие бизнес-решений.
Наша практика будет интересна, если:
- компания, в которой вы работаете, регулярно проводит закупки по прайс-листам, но зачастую приобретает не то, что нужно;
- вы стремитесь эффективнее отслеживать изменения цен в прайсах, но не готовы нанимать для этого новых сотрудников;
- вы хотите находить лучшие цены на товары быстро и с минимумом трудозатрат.
Если рядовой потребитель в поисках лучшего товара по лучшей цене отправляется в интернет, где на помощь приходит поисковик, то сотрудник компании вынужден изучать прайс-листы самостоятельно.
Мониторинг, анализ цен на товары и закупки осложняются тем, что поставщики часто используют
собственные форматы записи данных. Даже артикул в прайсах различных поставщиков может быть написан
На ручную обработку прайс-листов тратится рабочее время сотрудников. Ошибки, вызванные однообразием этой работы, влекут за собой переплаты и приобретение заведомо неподходящих по тем или иным параметрам товаров.
Число ошибок растет кратно объему обрабатываемой вручную информации, так что наибольшим рискам подвергаются производители и поставщики товаров. Они работают с прайсами постоянно, анализируют состояние рынка и следят за изменениями стоимости товаров конкурентов. Для них погрешности в расчетах, пропущенные корректировки цен на стороне конкурентов, нерелевантные выборки ведут не только к переплатам, но и к принятию неверных тактических и стратегических решений, которые ставят под удар весь бизнес.
Поэтому создание поискового сервиса по товарным прайсам, наряду с автоматизацией обработки несерийных потребностей заказчика, стало одной из ключевых задач в рамках комплексной системы управления закупками, над которой мы работали.
Как это работает
Для создания поисковика по товарным позициям и расценкам мы использовали алгоритмы машинного обучения, анализирующие прайсы и выполняющие полнотекстовый поиск по их содержимому.
Мы хотели, чтобы наш сервис в обращении был не сложнее поисковиков Яндекс или Google, и при этом точнее и быстрее человека. Ведь время на анализ цен и принятие решений часто ограничено: закрывается финансовый период, приближается запуск проекта или стремительно сокращаются запасы поставщика.
Концептуально сервис схож с функцией ранжирования Okapi BM25, часто используемой для сортировки поисковой выдачи, но при этом заточен под особенности работы с товарными позициями. Архитектура сервиса авторасценки и его интеграции в сервисы заказчика изображена на схеме.
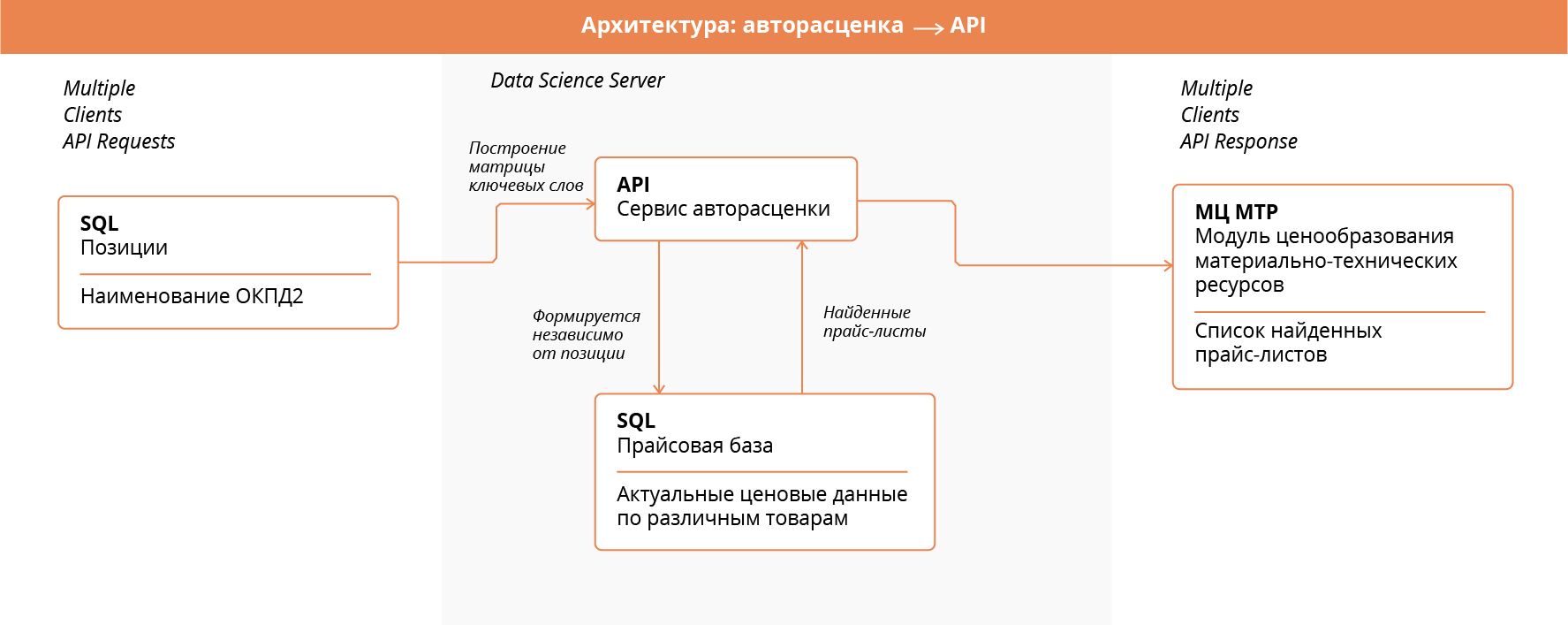
Прежде чем Data Science Server сумеет ответить на простейший пользовательский запрос, необходимо обработать содержимое прайсов, по которым будет проведен поиск.
Для этого составляется in-memory словарь с перечнем артикулов. Поскольку артикулы могут быть записаны
Перечень артикулов анализируется. Выявляются возможные форматы записи каждого артикула: с плюсами, пробелами и без них. Так словарь дополняется вариантами, которые встретятся в прайсах в будущем. Однако, одного словаря для поиска недостаточно. Зачастую точный артикул товара пользователю неизвестен, поэтому мы обучили сервис работать с запросами на естественном языке.
Исключив из прайсов артикулы, мы убираем из рассмотрения числительные и представляем оставшиеся данные, названия и различные характеристики товаров в виде разреженной матрицы. Такая форма сокращает нагрузку на сервер, проводящий обучение алгоритма, ускоряет эту процедуру.
Когда сервис получает запрос, алгоритм проводит независимый поиск и по словарю артикулов, и по матрице. В результатах поиска по словарю приоритет отдается совпадениям в редко встречающихся и длинных артикулах. Из них формируется первое множество результатов.
Одновременно с этим из пересечений по ключевым словам в матрице формируется второе множество результатов поиска. Здесь наибольший «вес» имеют совпадения в названиях, но учитываются и другие характеристики. Указание цвета, материала, массы товара также влияет на поисковую выдачу.
Чтобы показать пользователю только самые достоверные и релевантные запросу результаты, алгоритм сравнивает эти два множества, находит пересечения между ними и помещает на первые строчки поисковой выдачи.
Сервис с точки зрения пользователя

Работа алгоритмов незаметна пользователю. Интерфейс нашего сервиса, ждущая запроса поисковая строка, прост и интуитивно понятен. Стоит ввести запрос и кликнуть по кнопке «Авторасценка» — в течение 20 секунд получишь результат — ранжированный наименьшей цене список из тридцати наиболее подходящих под запрос товарных позиций. Единственное напоминание о том, что в основе системы алгоритм машинного обучения — возможность оценить результаты поиска по запросу.
Эта функция была предусмотрена для отладки алгоритма машинного обучения на ранних стадиях обучения. Уже тогда мы привлекали будущих пользователей к разработке, и вместе добивались улучшения поисковой выдачи. Тогда сервис еще работал в тестовом режиме, но когда он был запущен в полном объеме и стал доступен на персональных компьютерах наших партнеров, мы не стали отказываться от этой функции.
Увидев, что наименование, артикул или цена позиции не подходят под запрос, пользователь может отметить неверный параметр. Так он сообщит алгоритму о неточности. Обратная связь позволяет сервису совершенствоваться в процессе работы и со временем уточнять результаты выдачи по отдельным узким категориям товаров, интересующим конкретного пользователя.
Сервис спроектирован так, что легко масштабируется и способен обслуживать и потребности небольшой фирмы, и разом всех подразделений крупной компании.
Наши разработчики заранее настроили алгоритмы машинного обучения, на которых базируется поисковик, поэтому для запуска сервиса не требуется ничего, кроме серверных мощностей в облачном сервисе или офисе компании-заказчика.
Чтобы поиск заработал:
- Мы подготовим к работе back-end сервиса: развернем из Docker-контейнера Python-библиотеки, отвечающие за алгоритм поиска, настроим и запустим базу данных Microsoft SQL.
- Предоставим готовый пользовательский интерфейс или обеспечим интеграцию поисковика в уже существующие IT-системы заказчика.
- Проконсультируем по вопросам администрирования сервиса.
На весь комплекс работ потребуется около месяца, но ожидание того стоит. Автоматизированный поиск цен
на товары при помощи машинного обучения увеличивает производительность труда и помогает оптимизировать
трудозатраты. Он облегчает работу расценщиков и экономит средства, которые тратятся нерационально

