Классификация данных в системе управления закупками


Рассказываем о том, зачем внедрять в систему управления закупками машинное обучение, как оно помогает сэкономить время и силы сотрудников, и как настроить и развернуть сервис категоризации товаров на базе Open Source библиотек.
Наша практика будет интересна, если:
- вы работаете в средней или крупной компании со множеством подразделений;
- в отдел закупок вашей компании поступают обширные списки разнородных товаров, и он не справляется с нагрузкой;
- обработка товарных списков идет медленно и с ошибками;
- вы ищете способ сэкономить время и силы сотрудников, добиться большей эффективности труда.
Классификация — казалось бы, несложная задача. Легко понять, что бумага, чернила для принтеров, карандаши и линейки относятся к категории канцтоваров, а трубы и сварочные аппараты в этот ряд не вписываются. Тем не менее, в списках закупок крупной компании и те и другие позиции могут оказаться в одной категории.
Такого рода путаница не редкость. Люди неэффективно справляются с обработкой больших массивов данных, например, прайс-листов, и быстро теряют концентрацию.
На практике с этой проблемой сталкиваются поставщики и производители товаров, сотрудники торговых сетей и интернет-магазинов, а также работники отделов закупок компаний с множеством подразделений. Им ежедневно приходится работать с перечнями, где только число классов товаров достигает нескольких сотен, а счет разновидностям идет на тысячи. Все эти позиции необходимо не просто просмотреть, но и обработать, сопоставить принятую внутри организации классификацию с ОКПД2 — общероссийским классификатором продукции по видам экономической деятельности или прайс-листами поставщиков.
Такая рутина отнимает массу времени и сил сотрудников. Какой бы продолжительный срок ни был на нее отведен, неизбежны ошибки. Найти и устранить их в таблицах с тысячами строк — отдельная задача, зачастую еще более затратная.
Эти процессы стоит автоматизировать, но простые компьютерные алгоритмы плохо справляются «зашумленными» данными, а речь как раз о них. Товарные списки часто не унифицированы, в них в обилии встречаются разнообразные опечатки и описки, а одни и те же предметы могут иметь различные наименования.
Мы разработали эффективное решение проблемы классификации таких данных, когда создавали систему централизованного управления закупками для одного из наших заказчиков и его дочерних подразделений, справились с ней при помощи машинного обучения.
Преимущества автоматизации
Использование машинного обучения позволяет сэкономить силы и рабочее время сотрудников. Там, где раньше на ручную классификацию перечня закупок для филиалов компании уходил рабочий день, на разметку позиций при помощи алгоритма тратятся минуты.
Кроме того, наш сервис категоризации не допускает ошибок по невнимательности и в процессе работы накапливает опыт, самообучается, с каждым запросом выдает более точный результат, персонифицированный под нужды и специфику деятельности конкретного заказчика. Если поначалу алгоритм машинного обучения и допустит неточность, пользователю достаточно внести необходимые исправления, и они будут учтены системой.
Как это работает
Мы разбили процесс обработки и классификации товарных позиций на стадии.
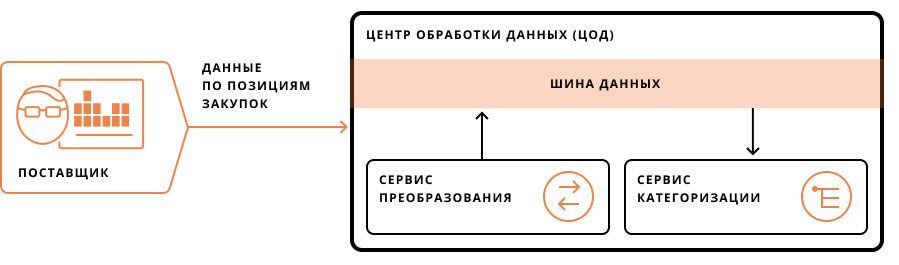
Сначала поставщики передают данные о товарах в центр обработки, откуда через шину, формирующую очередь задач, контролирующую их исполнение и логирующую эти процессы, информация поступает в сервис преобразования. Там данные по закупкам, представленные в различных форматах, упорядочиваются, очищаются от «шума» и форматируются так, чтобы было проще их обработать.
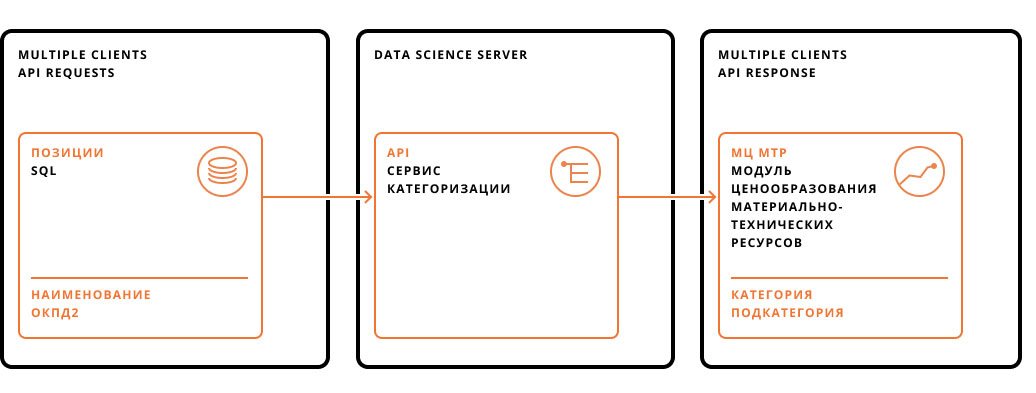
Затем в дело вступает алгоритм на базе модели машинного обучения, способный классифицировать объекты из исходного множества по различным критериям. Он обрабатывает строки закупок, присваивая им заранее заданные классы и подклассы, и возвращает результаты работы шине данных. Оттуда классифицированные позиции импортируются в сервис заказчика, где с ними можно работать дальше, провести расценку.
Алгоритм на базе модели машинного обучения использует составленный заказчиком классификатор — список позиций, по которым следует рассортировывать товарный набор.
Чаще всего в классификаторе используются такие значения, как наименование товара, данные из ОКПД2, марка, сорт, артикул и размер. Однако, алгоритм учитывает и различные ценовые данные, единицы измерения, ГОСТ, страну происхождения, предприятие-изготовитель — все значимые параметры, встречающиеся в товарных листах.
В основе нашего алгоритма — ансамбль из нескольких моделей прогнозирования, включающий в себя как деревья решений, так и другие модели, работающие совместно, дополняющие и подстраховывающие друг друга.
Выбранная нами архитектура, градиентный бустинг, подразумевает, что модели прогнозирования обучаются одна за другой, каждая последующая с учетом результатов и на ошибках предыдущей. На выходе это позволяет добиться высокой точности классификации за малое время.
Сервис написан на Python, на базе Open Source платформы для градиентного бустинга LightGBM, библиотеки XGBoost и разработанной исследователями и инженерами «Яндекс» открытой библиотеки CatBoost.
Внедрение сервиса категоризации
Разработка, написание и отладка обучающей модели заняли значительное время, но теперь мы предлагаем готовое решение, которое будет развернуто на серверных мощностях заказчика в сжатые сроки. Хотя классификатор создавался, как часть системы управления закупками, он спроектирован, как самодостаточный сервис, который без проблем интегрируется в уже существующую IT-инфраструктуру.
Процесс интеграции проходит в три этапа:
1. Настройка обучающей модели.
Для этого требуется товарный классификатор, принятый у заказчика, и обучающая выборка, где товарам уже присвоены правильные категории и подкатегории. Обработав эти данные, алгоритм формирует матрицу ключевых слов, которые связаны с категориями из товарного классификатора. Матрица — ключевой элемент сервиса. С ее помощью проводятся все последующие операции по категоризации.
2. Итеративное обучение.
На этом этапе мы анализируем результаты работы алгоритма машинного обучения с реальными данными, вносим необходимые доработки и убеждаемся, что сервис работает стабильно.
3. Запуск сервиса на серверах заказчика.
Мы упаковываем обученную модель в Docker-контейнер, чтобы облегчить обслуживание сервиса и оперативно развернуть его сразу со всеми необходимыми для работы компонентами без дополнительной настройки.
После активации сервиса заказчику остается только придумать, как распорядиться рабочим временем освободившихся сотрудников.
Машинное обучение — полезный инструмент, который подходит не только для упрощения категоризации. В следующей статье мы расскажем, как эта технология помогает искать выгодные цены на товары, необходимые компании.
Вам может быть интересно

Как мы работаем с новыми заказчиками — отвечаем на распространенные вопросы
Как мы работаем с новыми заказчиками — отвечаем на распространенные вопросы
Отвечаем на часто задаваемые вопросы о работе с компанией.
Классификация данных в системе управления закупками
Классификация данных в системе управления закупками
Рассказываем о том, зачем внедрять в систему управления закупками машинное обучение

